들어가기…
본 내용은 먼저 Kitematic을 설치 하셔야 하고 설치가 귀찮으시면 Kitematic부분을 CLI로 따라하셔도 무방 합니다. 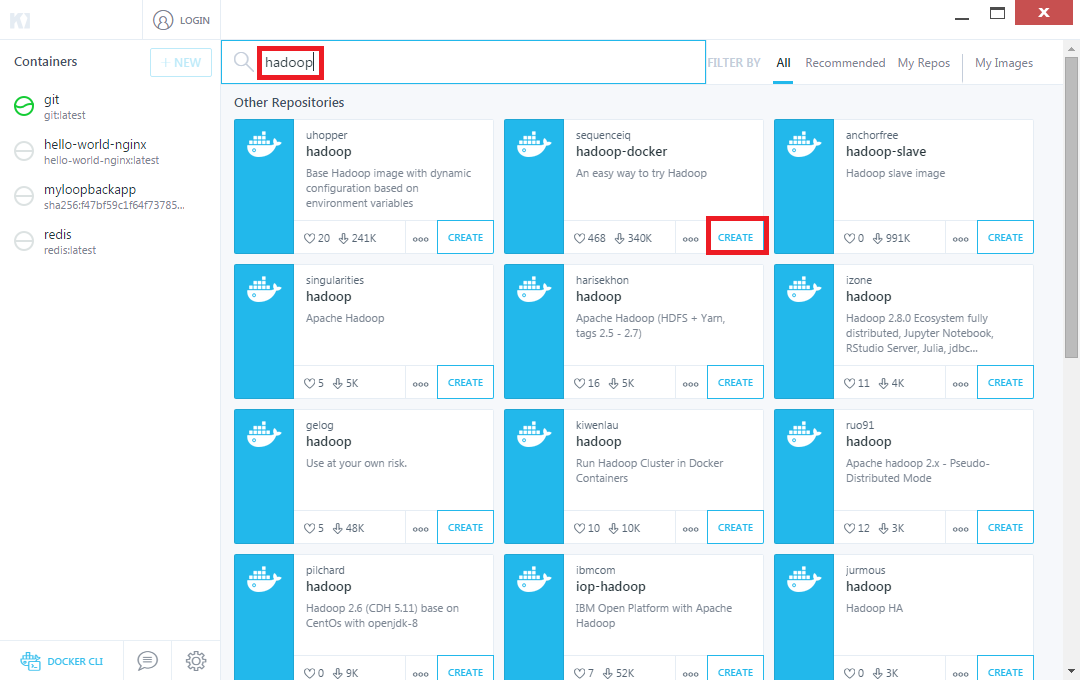 Kitematic을 실행 하신 후 image 검색에 ‘hadoop‘을 검색 합니다. 이중에서 자신이 원하는 image를 create버튼 클릭 하시면 로컬에 image가 다운로드 됩니다. (cli에서는 docker pull 사용)
Kitematic을 실행 하신 후 image 검색에 ‘hadoop‘을 검색 합니다. 이중에서 자신이 원하는 image를 create버튼 클릭 하시면 로컬에 image가 다운로드 됩니다. (cli에서는 docker pull 사용) 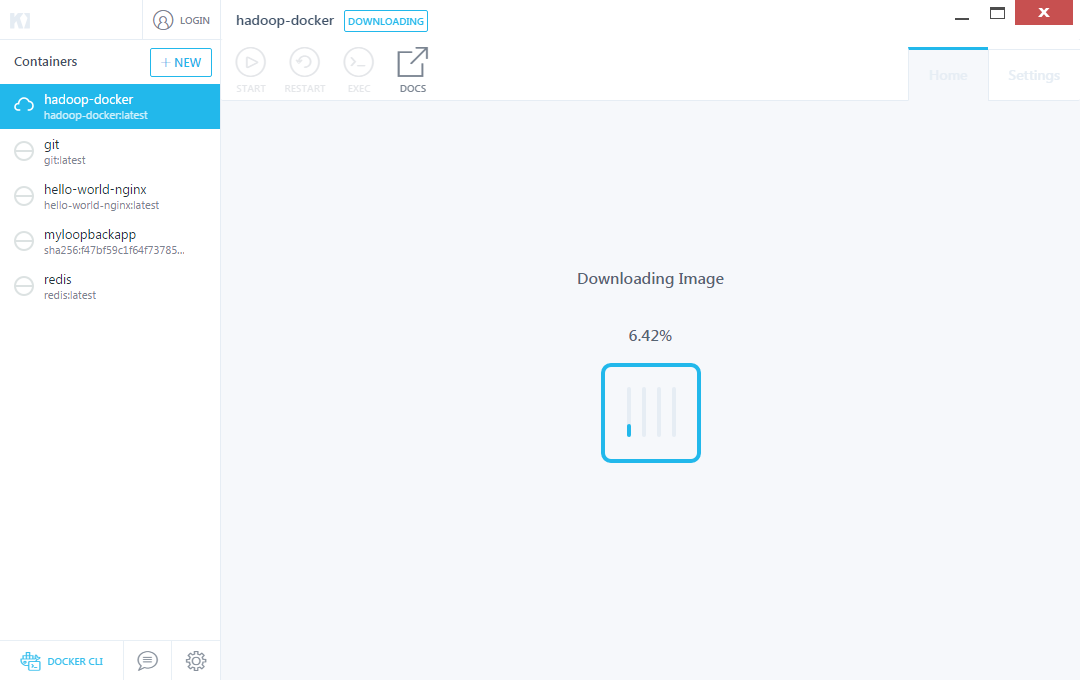 create클릭 후 곧바로 image를 다운로드 하며 다운로드 후 컨테이너까지 생성(docker run) 해줍니다.
create클릭 후 곧바로 image를 다운로드 하며 다운로드 후 컨테이너까지 생성(docker run) 해줍니다. 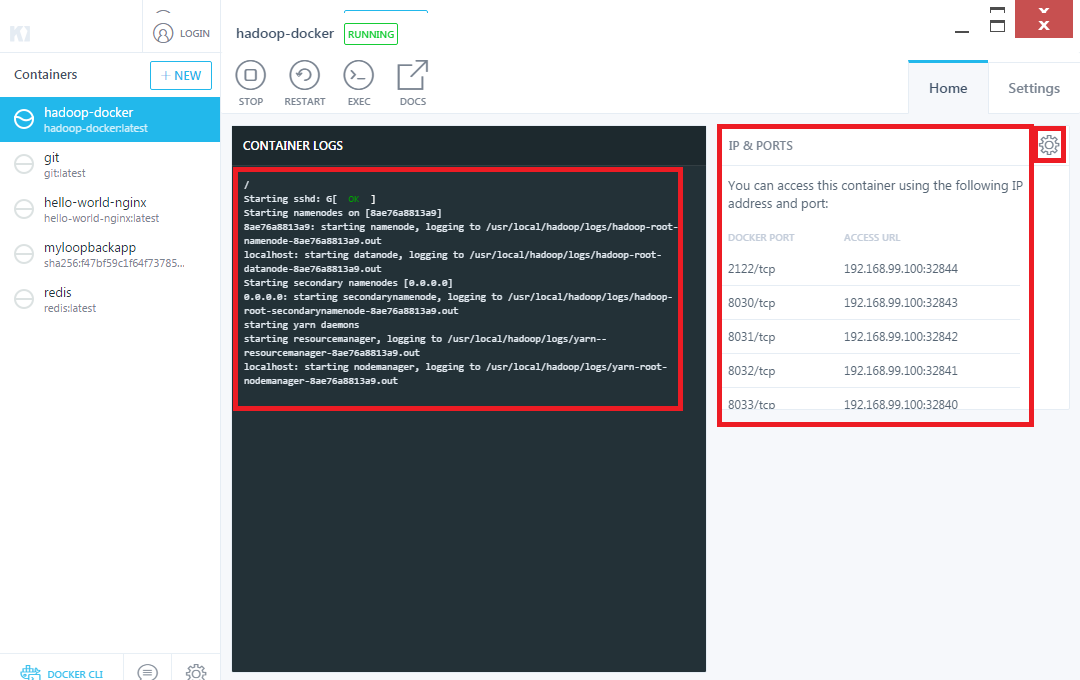 컨테이너 까지 생성이 되면 가운데엔 log가 나오며 오른쪽엔 호스트와 컨테이너간의 포트 매핑된 모습을 볼수 있습니다.
컨테이너 까지 생성이 되면 가운데엔 log가 나오며 오른쪽엔 호스트와 컨테이너간의 포트 매핑된 모습을 볼수 있습니다. 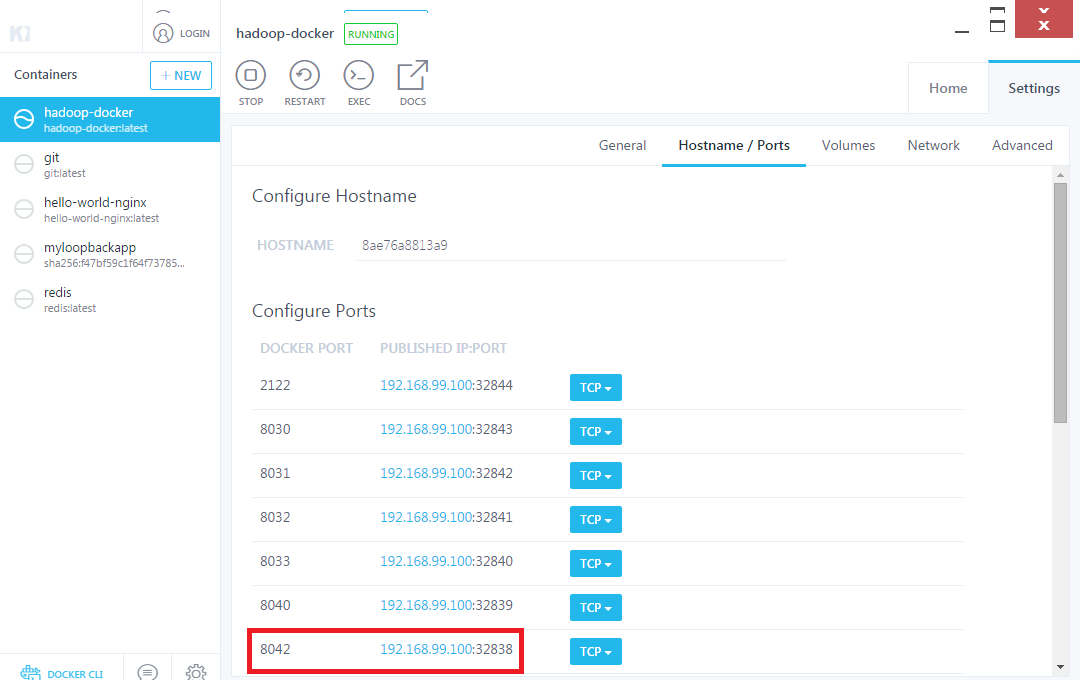
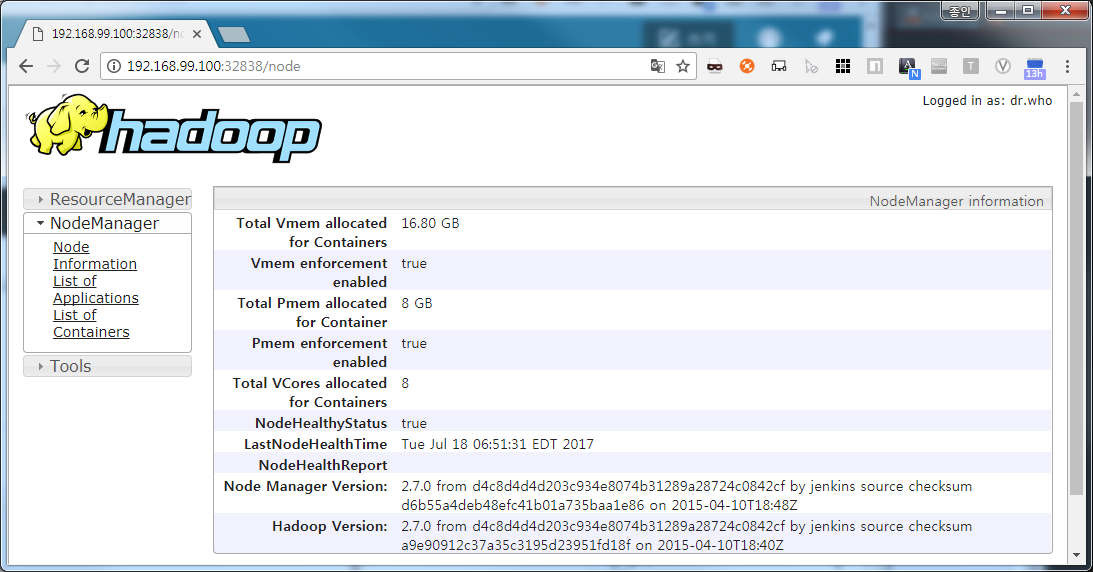 톱니바퀴 클릭후 호스트포트:컨테이너포트 매핑된걸 클릭하시면 연결된 웹페이지도 열리므로 나중에 어떤 포트가 열려 있는지 확인 하시면 좋을거 같습니다.
톱니바퀴 클릭후 호스트포트:컨테이너포트 매핑된걸 클릭하시면 연결된 웹페이지도 열리므로 나중에 어떤 포트가 열려 있는지 확인 하시면 좋을거 같습니다. 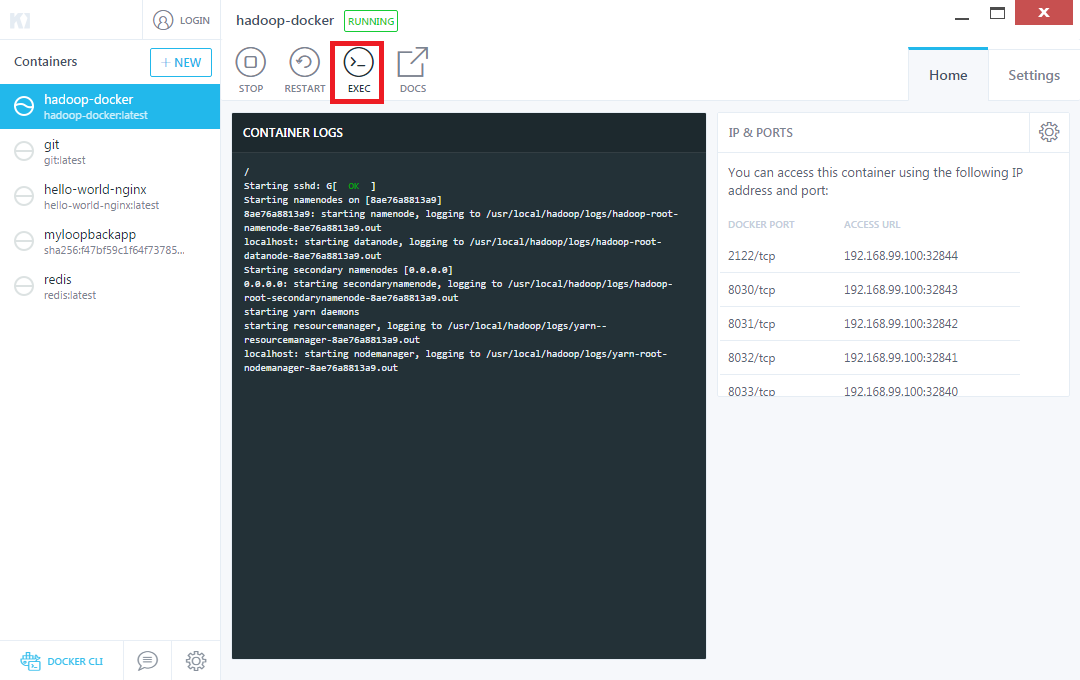 위에 있는 EXEC버튼을 클릭 하시면
위에 있는 EXEC버튼을 클릭 하시면  각 OS에 맞는 CLI가 나옵니다. 여기서 부턴 컨테이너OS에 맞는 명령어를 치시면 컨테이너의 기능을 사용 하실수 있습니다. 본격적으로 hadoop 워드카운트 예제를 실행해 보겠습니다.
각 OS에 맞는 CLI가 나옵니다. 여기서 부턴 컨테이너OS에 맞는 명령어를 치시면 컨테이너의 기능을 사용 하실수 있습니다. 본격적으로 hadoop 워드카운트 예제를 실행해 보겠습니다.
Hadoop 워드 카운트 예제
hadoop 워드 카운트 예제는
- 예제용 데이터 생성
- 예제용 데이터 HDFS에 삽입
- 워드 카운트 예제 실행
- 결과 확인
순으로 실행할 예정 입니다. 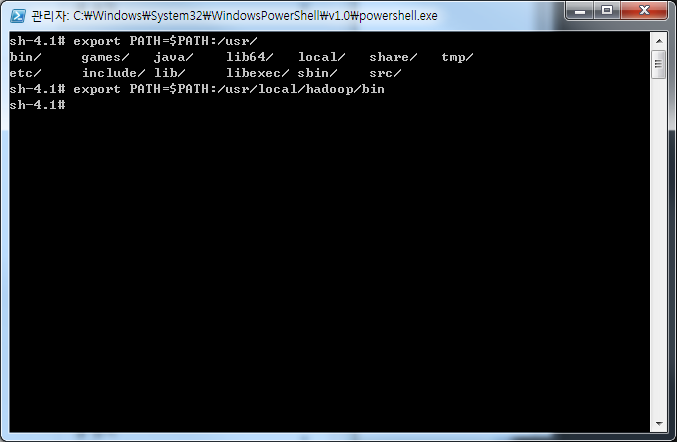 하듑 명령어 실행의 편의성을 위해 PATH환경 변수를 추가 해 줍니다.
하듑 명령어 실행의 편의성을 위해 PATH환경 변수를 추가 해 줍니다. 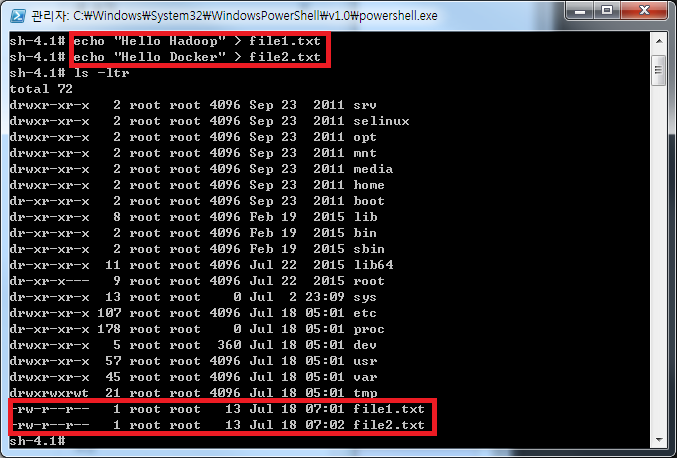 예제에 쓰일 테스트 데이터를 저장 합니다(Hello Hadoop, Hello Docker)
예제에 쓰일 테스트 데이터를 저장 합니다(Hello Hadoop, Hello Docker) 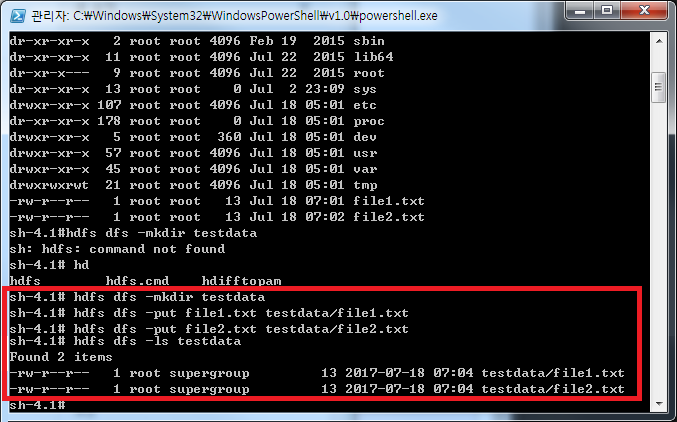 hdfs명령어를 통해 Hadoop File System에 디렉토리 생성 및 테스트 파일을 넣어주고
hdfs명령어를 통해 Hadoop File System에 디렉토리 생성 및 테스트 파일을 넣어주고 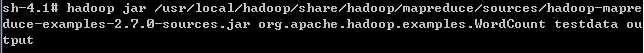 hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/sources/hadoop-mapre duce-examples-2.7.0-sources.jar org.apache.hadoop.examples.WordCount testdata output 를 실행 합니다.
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/sources/hadoop-mapre duce-examples-2.7.0-sources.jar org.apache.hadoop.examples.WordCount testdata output 를 실행 합니다. 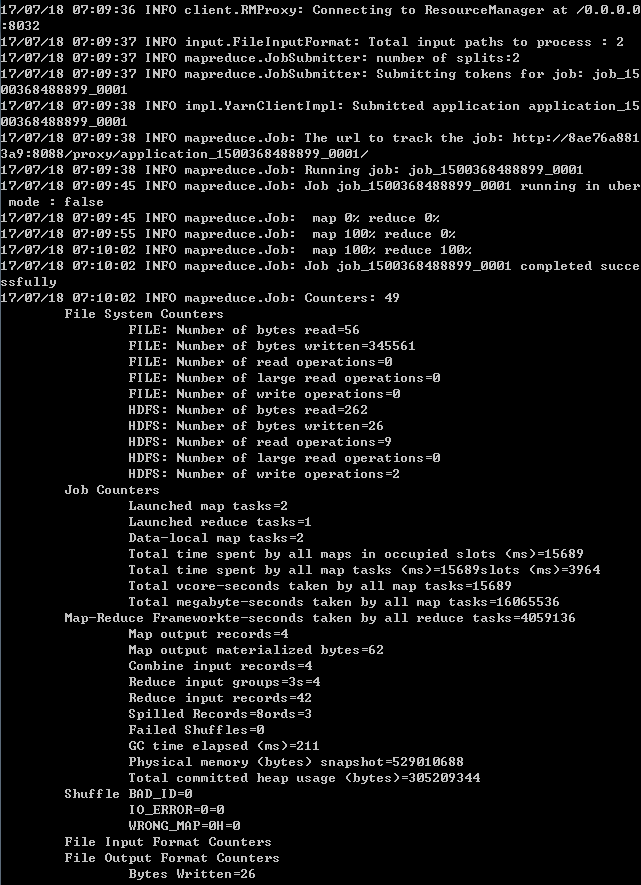 워드 카운트 예제를 돌린 로그가 뜨고
워드 카운트 예제를 돌린 로그가 뜨고  hdfs dfs -cat 명령어를 통해 워드 카운트 예제 결과를 확인 할 수 있습니다. Hadoop MapReduce에 대해 알고 싶으신 분들은 공식 홈페이지를 참조하시면 좋을거 같습니다. http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
hdfs dfs -cat 명령어를 통해 워드 카운트 예제 결과를 확인 할 수 있습니다. Hadoop MapReduce에 대해 알고 싶으신 분들은 공식 홈페이지를 참조하시면 좋을거 같습니다. http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html

