Spring Data 프로젝트는 Spring Framework를 둘러싼 생태계의 일부이며 고급 데이터 액세스와 관련된 주제를 다루는 포괄적 인 프로젝트입니다. 여기에는 일반 관계형 데이터 저장소 (일반 JDBC 또는 JPA 기반), NoSQL (MongoDB, Neo4j 또는 Redis) 및 Apache Hadoop과 같은 대형 데이터 기술을 지원하는 모듈이 포함되어 있습니다. 이 프로젝트의 핵심 사명은 상점 별 특징과 기능을 유지하면서 다양한 데이터 액세스 기술을위한 친숙하고 일관된 스프링 기반 프로그래밍 모델을 제공하는 것입니다.
특징
인프라 구성 지원
모든 Spring Data 프로젝트의 핵심 주제는 데이터 액세스하기위한 환경 설정을 지원하는 것입니다. 이 지원은 XML 네임 스페이스와 Spring JavaConfig를위한 지원 클래스를 사용하여 구현되어 Mongo DB, embedded Neo4j instance 등에 대한 액세스를 쉽게 설정할 수 있습니다. 또한 JMX(Java Management eXtensions)와 같은 핵심 Spring 기능 통합이 제공됩니다. 또한 JMX와 같은 core Spring 기능과의 통합이 제공됩니다. 즉, 일부 저장소는 Spring API를 통해 JMX에 노출되는 고유 API를 통해 통계를 노출합니다.
객체 매핑 프레임 워크
대부분의 NoSQL Java API는 도메인 오브젝트를 저장소의 데이터 모델 (예 : MongoDB의 Document 또는 Neo4j의 Node 및 relationships)에 맵핑하는 지원을 제공하지 않습니다. 따라서 네이티브 Java 드라이버를 사용하여 작업 할 때는 일반적으로 읽을 때 응용 프로그램의 도메인 객체에 데이터를 매핑하기 위해 상당한 양의 코드를 작성해야하며, 그 반대의 경우도 마찬가지입니다. 따라서 Spring Data 프로젝트의 핵심 부분은 매핑 및 변환 API로서 도메인 클래스에 대한 메타 데이터를 유지하여 영구 도메인 객체를 저장소 특정 데이터 유형으로 변환 할 수 있도록합니다.
템플릿 API
객체 매핑 API 위에는 Spring의 JdbcTemplate, JmsTemplate 등에서 이미 잘 알려진 템플릿 패턴 구현 형태로 유명한 API가 있습니다. 따라서 RedisTemplate, MongoTemplate 등이 있습니다. 이러한 템플릿은 적절한 리소스 관리 및 예외 변환을 자동으로 처리하면서 단일 명령문으로 개체를 지속하는 것과 같이 일반적으로 필요한 작업을 실행할 수있는 도우미 메서드를 제공합니다. 그 외에도 store-native API에 액세스 할 수있는 콜백 API를 노출하면서 예외는 변환되고 리소스는 적절하게 관리됩니다.
Repository 추상화
이러한 기능은 기존 데이터베이스와 마찬가지로 데이터 액세스 계층을 구현하기위한 toolbox를 제공합니다. Spring Data는 데이터 액세스 레이어의 개발을 단순화하기 위해 템플릿 구현 위에 Repository 추상화를 제공합니다. 따라서 표준 CRUD 작업 수행 및 실행과 같은 가장 일반적인 시나리오에 대한 일반 interface 정의를 작성하기 위해 데이터 액세스 개체를 구현하려는 노력이 줄어 듭니다. 이 데이터 액세스 레이어 추상화는 여러 저장소에서 CRUD 작업을위한 이식성 계층을 제공하지만 MongoDB의 geo-spatial 쿼리와 같은 특정 기능을 저장하는 데 제한되지 않습니다. 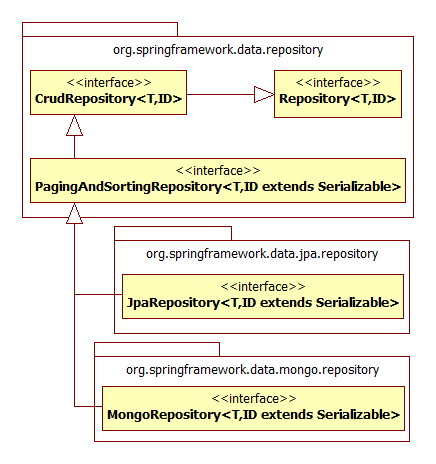 스프링 데이터 리파지토리 추상화에서 중심적인 인터페이스는 Repository입니다.이것은 도메인클래스와 도메인의 id 타입을 타입아규먼트로 받습니다. 이 인터페이스는 주로 마커 인터페이스로 동작하며, 작업할 타입을 가지고 있으면서, 당신이 이것을 확장할 인터페이스를 발견하게 해줍니다. CrudRepository 는 관리되는 엔티티클래스에서 복잡한 CRUD기능을 제공해줍니다.
스프링 데이터 리파지토리 추상화에서 중심적인 인터페이스는 Repository입니다.이것은 도메인클래스와 도메인의 id 타입을 타입아규먼트로 받습니다. 이 인터페이스는 주로 마커 인터페이스로 동작하며, 작업할 타입을 가지고 있으면서, 당신이 이것을 확장할 인터페이스를 발견하게 해줍니다. CrudRepository 는 관리되는 엔티티클래스에서 복잡한 CRUD기능을 제공해줍니다.
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> { S save(S entity); //주어진 엔티티를 저장합니다. T findOne(ID primaryKey); //주어진 아이디로 식별된 엔티티를 반환합니다. Iterable findAll(); //모든 엔티티를 반환합니다. Long count(); //엔티티의 숫자를 반환합니다. void delete(T entity); //주어진 엔티티를 삭제합니다. boolean exists(ID primaryKey); //주어진 아이디로 엔티티가 존재하는지를 반환합니다. // … more functionality omitted. }
그다음 확장된 PagingAndSortingRepository 는 페이징 처리 및 소팅 기능을 첨부하였습니다.
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> { Iterable findAll(Sort sort); Page findAll(Pageable pageable); }
그 이외 Spring data commons와 함께 쓰는 JPA와 MongDB 등등 은 PagingAndSortingRepository 를 상속 받아서 저장소 고유의 메서드를 정의 하였습니다.
@NoRepositoryBean public interface JpaRepository<T, ID extends Serializable> extends PagingAndSortingRepository<T, ID> { public List findAll(); public List findAll(Sort paramSort); public List findAll(Iterable paramIterable); public List save(Iterable paramIterable); public void flush(); public S saveAndFlush(S paramS); public void deleteInBatch(Iterable paramIterable); public void deleteAllInBatch(); public T getOne(ID paramID); }

